This is part of the VMware vSAN guide post series. By using the following link, you can access and explore more objectives from the VMware vSAN study guide.
In the previous post, we successfully configured a vSAN Cluster. Now, we are all set to create virtual machines in this cluster and utilize the vSAN datastore. One of the critical options that play an important role during the creation or migration of a virtual machine is the VM Storage Policy. But what exactly is it, and how does it affect virtual machines and their relation with vSAN? Stay with me as I explain it in more detail.
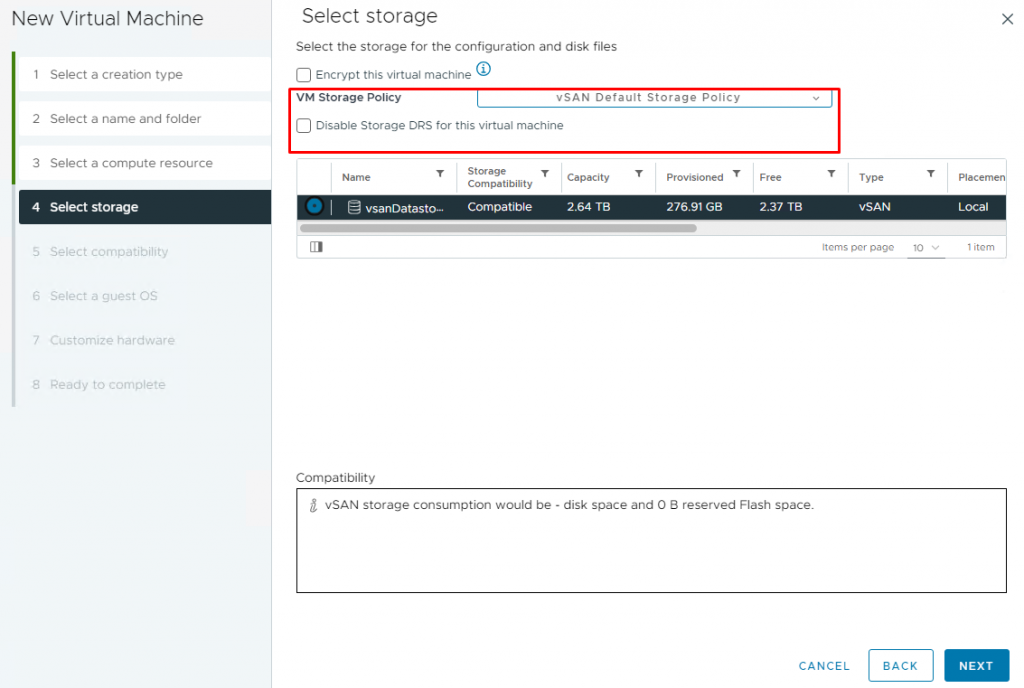
A VM storage policy serves as a blueprint for defining how virtual machines (VMs) and their associated objects are stored and protected within the cluster. It provides a granular level of control over various storage aspects, such as performance, availability, and data protection, allowing administrators to customize the behavior of their virtual infrastructure to meet diverse workload demands.
As mentioned earlier, every virtual machine in a vSAN datastore comes with a VM Storage Policy, even if you didn’t explicitly select one during its creatio, it automatically uses the vSAN Default Storage Policy. Therefore, every virtual machine has a VM storage policy associated with it. Now, let’s take a closer look at what this policy entails and what settings are included in it.
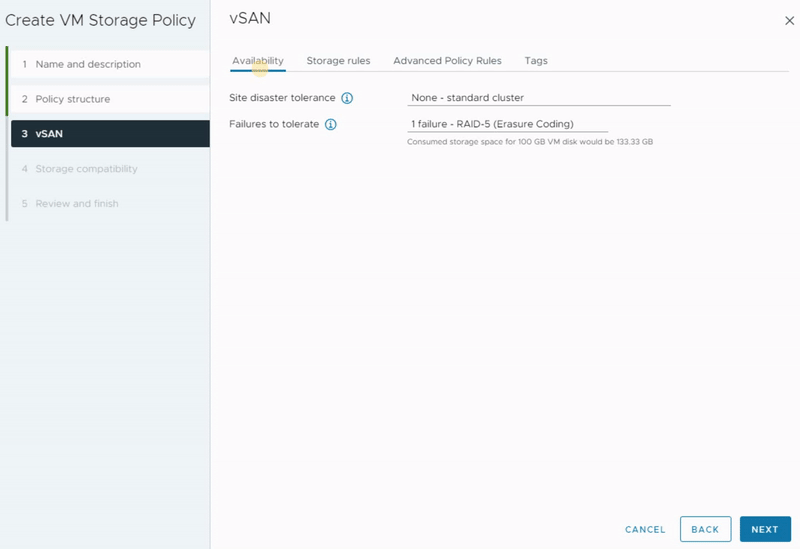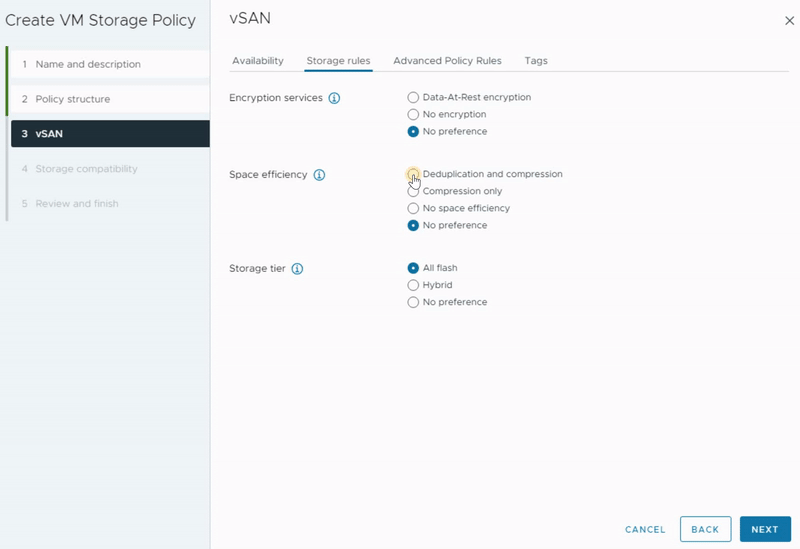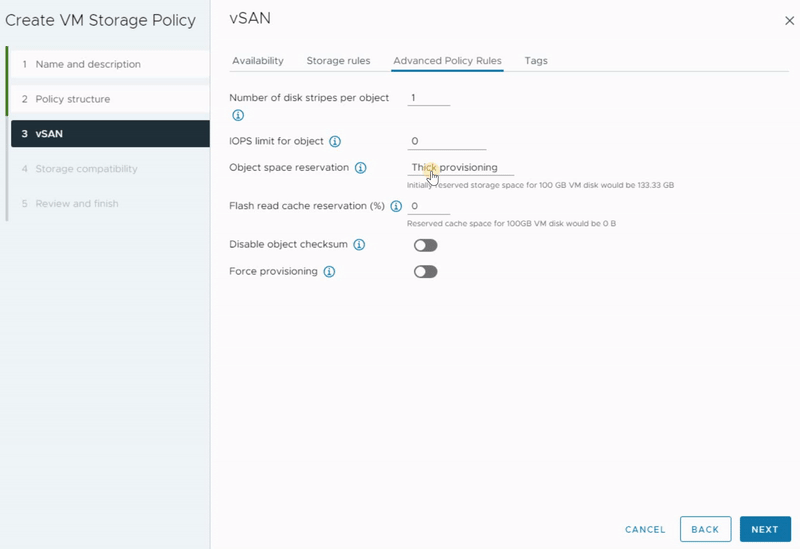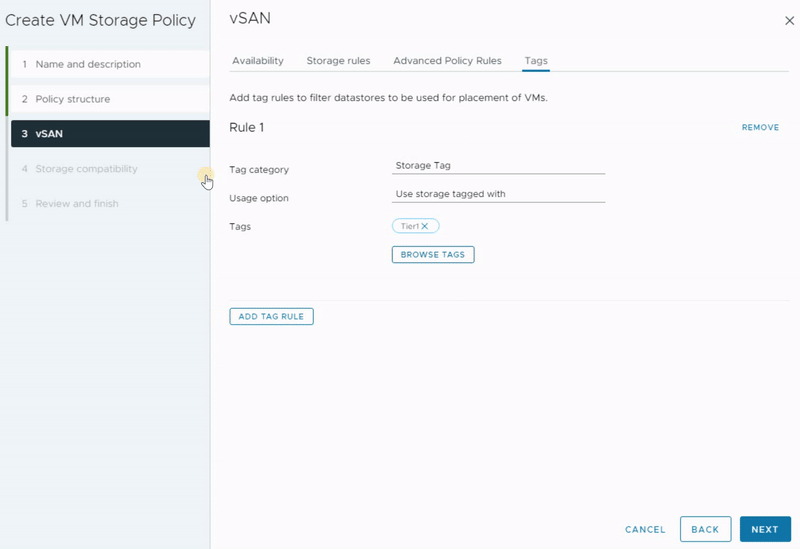
As you can see, there are four different tabs that allow you to define availability and redundancy, performance and capacity, security features, and some advanced settings. Additionally, you have the option to set storage affinity according to your preferences.
In this post, I will explore the first tab and aim to provide a comprehensive overview of all the available configuration options. By the end, you’ll have a clear vision of the different types of configurations offered in this section.
Site disaster tolerance
In the first tab, you have two configuration settings. The first one is Site disaster tolerance which refers to the ability of a vSAN cluster to withstand the failure of an entire site without losing data or disrupting VM operations. In a multi-site vSAN environment, data is distributed and replicated across various physical locations which provides protection against site failures, including natural disasters, power outages, or network failures.
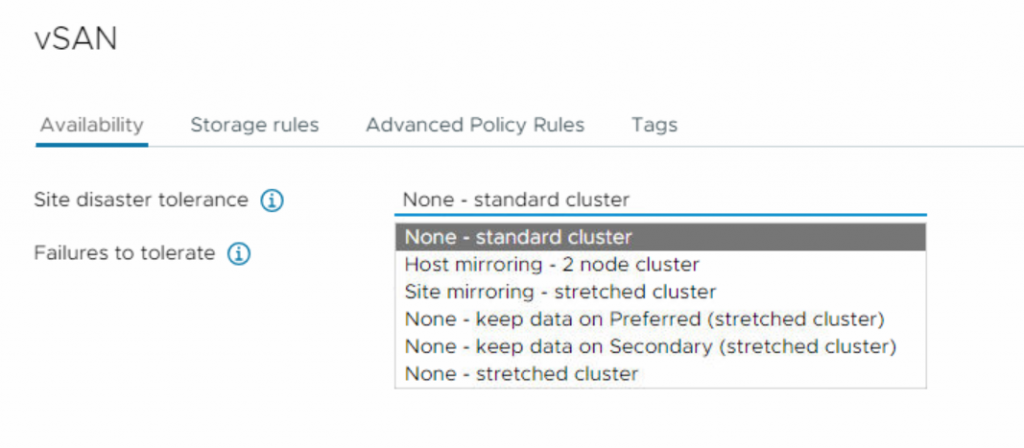
None (standard cluster): This is the default value and It does not provide disaster tolerance.
Host Mirroring (2-node cluster): This setting is used when you are using 2 node cluster and enables the replication inside a single host in a 2 Node cluster. Each data host must have at least three disks in a storage pool to use this rule.
Site mirroring (stretched cluster): The data is distributed and replicated across both sites, providing protection against site-wide failures. If one site goes down due to a natural disaster, power outage, or network failure, the other site continues to handle the VM operations and data access. This setup ensures high availability and minimal data loss during site failures.
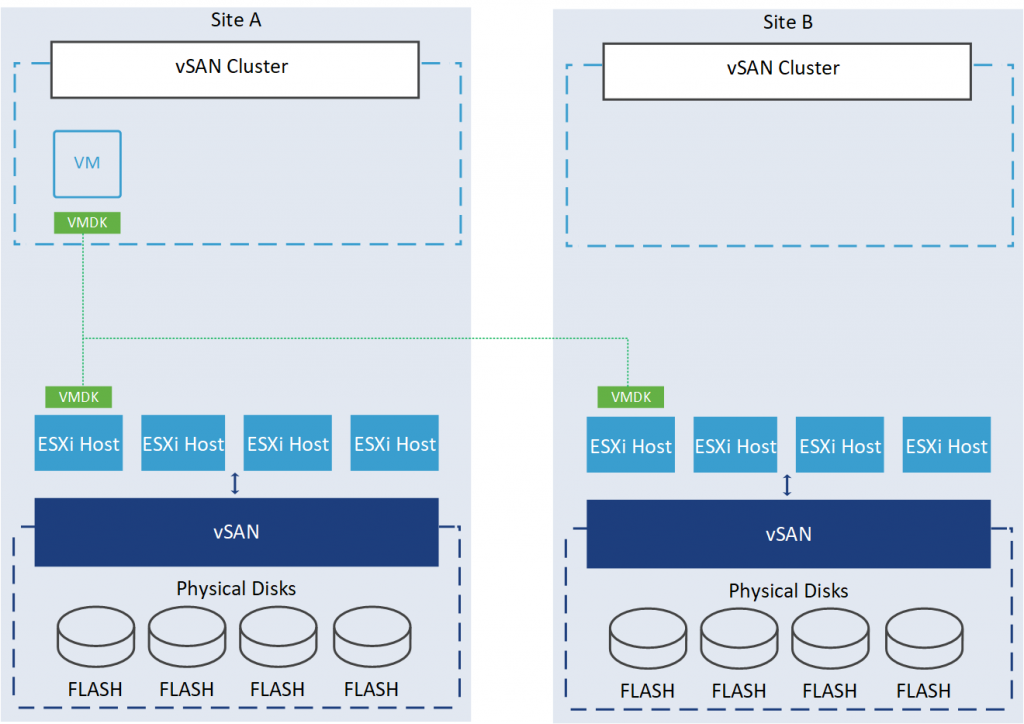
None – keep data on Preferred (stretched cluster): This setting is used when you need to pin data to a specific site. For instance, if you are utilizing Big Data technologies like Hadoop, Spark, or NoSQL, which maintain data redundancy at the application layer, you may wish to avoid replicating this virtual machine and instead pin it to a single site, in this case, the primary site.
For the proper deployment of this setting, you must consider turning off vSphere DRS and HA options to prevent the automated movement of VMs.
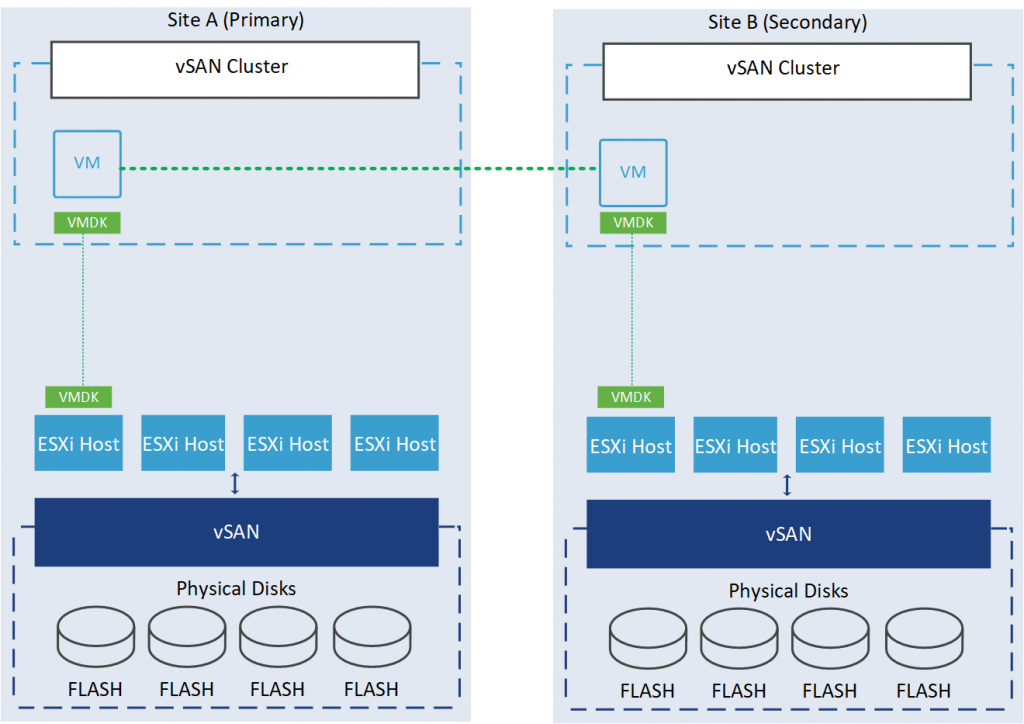
None – keep data on Secondary (stretched cluster). This setting is similar to the option mentioned above, with the only difference being that, in this case, the virtual machine is pinned to the secondary site.
None – stretched cluster: This setting provides no site resiliency protection; it only uses one site to store data, and the vSAN cluster will automatically handle the data distribution between the two sites based on factors such as storage capacity and performance. If a catastrophic event occurs at the site where the cluster is located, the data may be at risk, and VM operations may be disrupted until the issue is resolved.
Failures to tolerate
vSAN Storage Policies offer a variety of availability and redundancy options to meet the needs of different applications. Administrators can define the number of failures to tolerate often abbreviated as FTT, which determines how many copies of a VM’s data are maintained in the vSAN cluster. In case of hardware failures or maintenance events, the VMs remain protected and continue to operate seamlessly, safeguarding against data loss and minimizing downtime. Depending on the Site disaster tolerance option you selected, the level of Failures to tolerate will vary. In the case of a stretched cluster, it defines the number of disk or host failures that can be tolerated for each of the sites. For non-stretched clusters, it defines the number of disk failures, host failures, or fault domains that can be tolerated.
What is a Fault Domain? Allow me to provide a complete explanation of it at the end of this post.
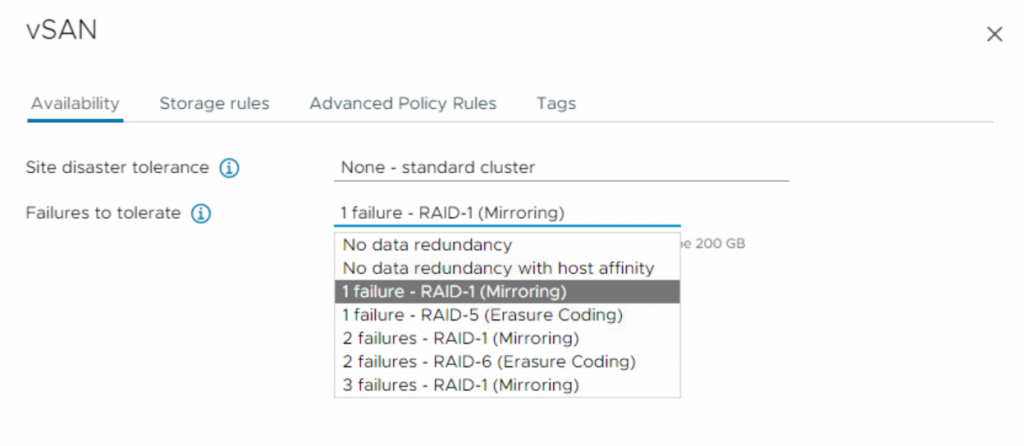
As you might notice, there are two replication methods: RAID-1 (Mirroring), and RAID-5/6 (Erasure Coding). RAID-1 (Mirroring) uses more disk space to store redundant copies of objects, but it provides better performance for accessing these objects. On the other hand, RAID-5/6 (Erasure Coding) uses less disk space, but its performance is relatively reduced. However, in vSAN ESA, you can achieve erasure coding efficiency at RAID-1 performance! This might seem unbelievable, but it’s due to the innovative way the new architecture (Express Storage Architecture) handles I/O.
No data redundancy: This option provides no protection for virtual machine objects and you may lose data when the vSAN cluster encounters a device or host failure. Entering hosts in maintenance mode is also taking time since vSAN must evacuate the object from the host for the maintenance operation to complete successfully.
The capacity consumption depends on the site disaster tolerance you are selecting.
| Site Disaster Tolerance | Capacity Consumption |
|---|---|
| None (standard cluster) | Tolerate no failure, consumes 1x the capacity of the primary data |
| Host Mirroring (2-node cluster) | Tolerate a single host failure, consumes 2x the capacity of the primary data |
| Site mirroring (stretched cluster) | Tolerate a site failure, consumes 2x the capacity of the primary data |
No data redundancy with host affinity: This option is designed for situations when you need to bind data to a specific host. For instance, when utilizing Big Data technologies like Hadoop, Spark, or NoSQL, along with other applications that maintain data redundancy at the application layer, you might not want to replicate this virtual machine. This option is available only for None-Standard Cluster or None-Stretched Cluster.
1 failure – RAID-1 (Mirroring): This option tolerates the failure of one host or device and protects a virtual machine object by creating a replica object with the original size using raid 1 technology. For a virtual machine with 100GB, it creates another 100 GB replica. However, the number of replicas and capacity consumption depends on the site disaster tolerance you are selecting.
| Site Disaster Tolerance | Capacity Consumption |
|---|---|
| None (standard cluster) | Tolerate a host failure, consumes 2x the capacity of the primary data |
| Host Mirroring (2-node cluster) | Tolerate a host failure and one disk in the remaining host, consumes 4x the capacity of the primary data, it means each host has 2 replica! |
| Site mirroring (stretched cluster) | Tolerate a host or disk failure in each site, consumes 4x the capacity of the primary data, it means each site has 2 replica! |
1 failure – RAID-5 (Erasure Coding): Specify this option if your VM object can tolerate one host or device failure by utilizing RAID-5 technology. For vSAN Object Storage Architecture (OSA), to protect a 100 GB VM object using RAID-5 (Erasure Coding) with an FTT of 1, you will consume 133.33 GB and a minimum of 4 hosts is required. This means that the data is written as a stripe consisting of 3 data bits and 1 parity bit across at least 4 hosts.
Here, I only take into account vSAN ESA, so all assumptions are based on this architecture.
On the other hand, vSAN Express Storage Architecture (ESA) creates an optimized RAID-5 format based on the cluster size. If the number of hosts in the cluster is less than 6, vSAN creates a RAID-5 (2+1) format. If the number of hosts is greater than 6, vSAN uses a RAID-5 (4+1) format. Additionally, if you expand or shrink the cluster, the format will be automatically readjusted within 24 hours after the change.
The following picture shows the RAID-5 2+1 (2 Data + 1 Parity) and 4+1 (4 Data + 1 Parity) schema.
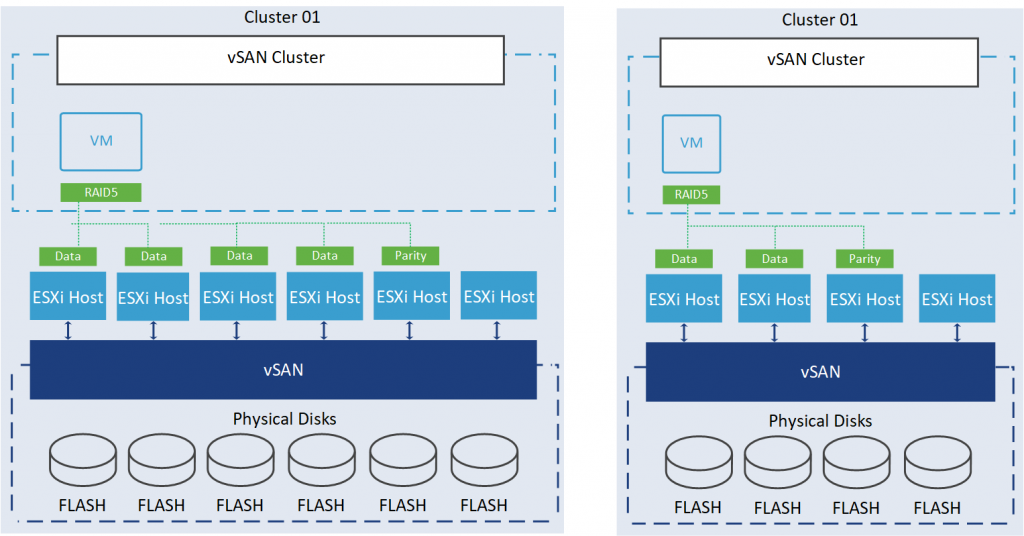
Capacity consumption depends on the site disaster tolerance you are selecting.
| Site Disaster Tolerance | Capacity Consumption |
|---|---|
| None (standard cluster) | Tolerate a host failure, consumes 1.33x the capacity of the primary data |
| Host Mirroring (2-node cluster) | Tolerate a host failure and one disk in the remaining host, consumes 2.66x the capacity of the primary data |
| Site mirroring (stretched cluster) | Tolerate a host or disk failure in each site, consumes 2,66x the capacity of the primary data |
2 failures – RAID-1 (Mirroring): Specify this option if your VM object can tolerate up to two device failures using miroring technology. Since you need to have a FTT of 2 using RAID-1 (Mirroring), there is a capacity overhead that may be too high for some cases. The decision to use it depends on the specific situations and requirements.
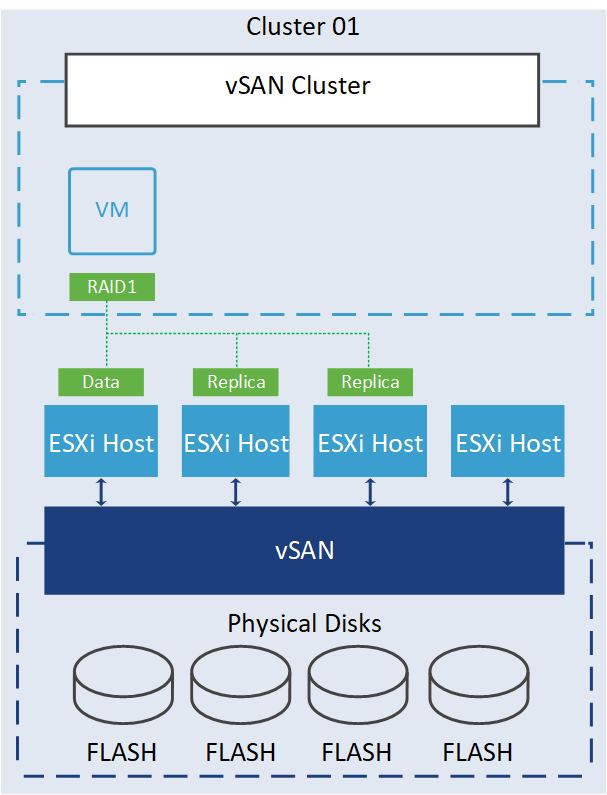
Capacity consumption depends on the site disaster tolerance you are selecting.
| Site Disaster Tolerance | Capacity Consumption |
|---|---|
| None (standard cluster) | Tolerate two host failure, consumes 3x the capacity of the primary data |
| Host Mirroring (2-node cluster) | Tolerate a host failure and two disks in the remaining host, consumes 6x the capacity of the primary data |
| Site mirroring (stretched cluster) | Tolerate two hosts or disks failure in each site, consumes 6x the capacity of the primary data |
2 failures – RAID-6 (Erasure Coding): Choose this option if your VM objects can tolerate up to two device failures. To protect a 100 GB VM object using RAID-6 (Erasure Coding) with an FTT of 2, you will require 150 GB of storage. As you can see in the following image, the data is written as a stripe consisting of 4 data bits and 2 parity bits, distributed across a minimum of 6 hosts.
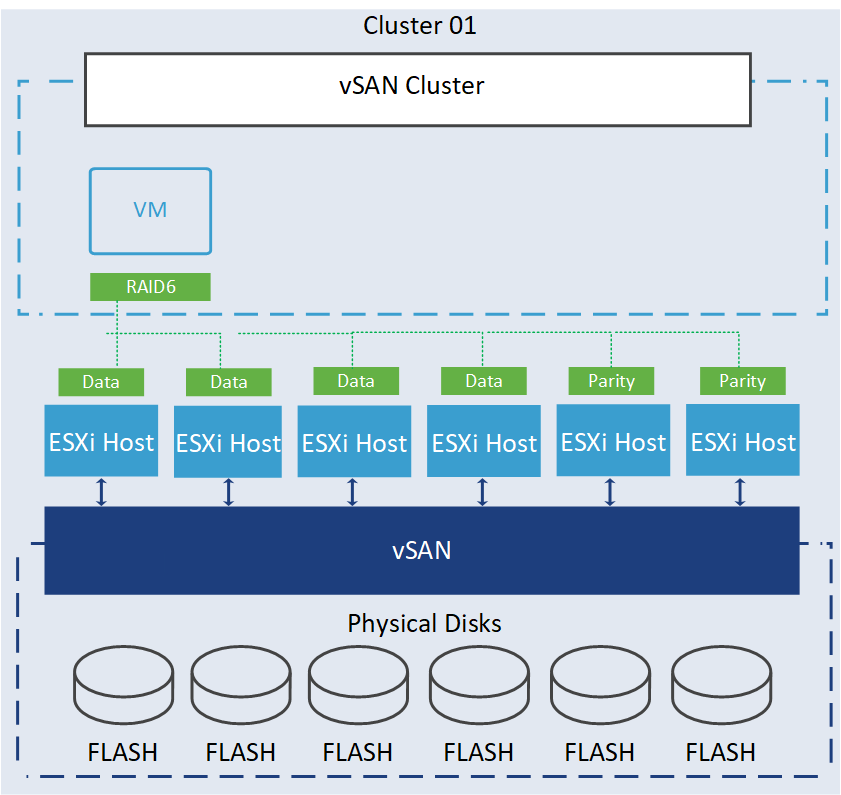
Capacity consumption depends on the site disaster tolerance you are selecting.
| Site Disaster Tolerance | Capacity Consumption |
|---|---|
| None (standard cluster) | Tolerate two hosts failure, consumes 1,5x the capacity of the primary data |
| Host Mirroring (2-node cluster) | Tolerate a host failure and two disks in the remaining host, consumes 3x the capacity of the primary data |
| Site mirroring (stretched cluster) | Tolerate two hosts or disks failure in each site, consumes 3x the capacity of the primary data |
3 failures – RAID-1 (Mirroring): Specify this option if your VM objects can tolerate up to three hosts or disk failures using miroring technology, which may introduce a capacity overhead that is too high for normal workloards. In rare situation, you may need this options.
Capacity consumption depends on the site disaster tolerance you are selecting.
| Site Disaster Tolerance | Capactiy Consumption |
|---|---|
| None (standard cluster) | Tolerate three hosts failure, consumes 3x the capacity of the primary data |
| Host Mirroring (2-node cluster) | Tolerate a host failure and 3 disks in the remaining host, consumes 8x the capacity of the primary data |
| Site mirroring (stretched cluster) | Tolerate three hosts or disks failure in side each site, consumes 8x the capacity of the primary data |
As you can see, FTT can be configured at the VM level using storage policies to determine the number of replicas that should be created for each VM’s data. The available options for FTT are 1, 2, or 3. The higher the FTT value, the more replicas are maintained, resulting in greater data redundancy but potentially impacting usable storage capacity.
By combining site disaster tolerance with appropriate FTT settings, you can design a highly available and resilient vSAN environment that protects against both site-wide failures and individual host failures.
Fault Domains
Let’s discuss the concept of fault domains. I’ve mentioned it several times, and now it’s a good time to explain this term in detail. A fault domain refers to a logical grouping of vSAN hosts and their associated storage devices based on their physical location in the data center. Fault domains enable vSAN to tolerate failures of entire physical racks as well as failures of a single host, capacity device, network link, or network switch dedicated to a fault domain.
By understanding and setting up fault domains properly, VMware vSAN can optimize data placement, data replication, and failure handling, providing a more robust and resilient solution. Let’s consider an example of a VMware vSAN cluster in a data center with three racks, each containing three hosts with their associated storage devices.
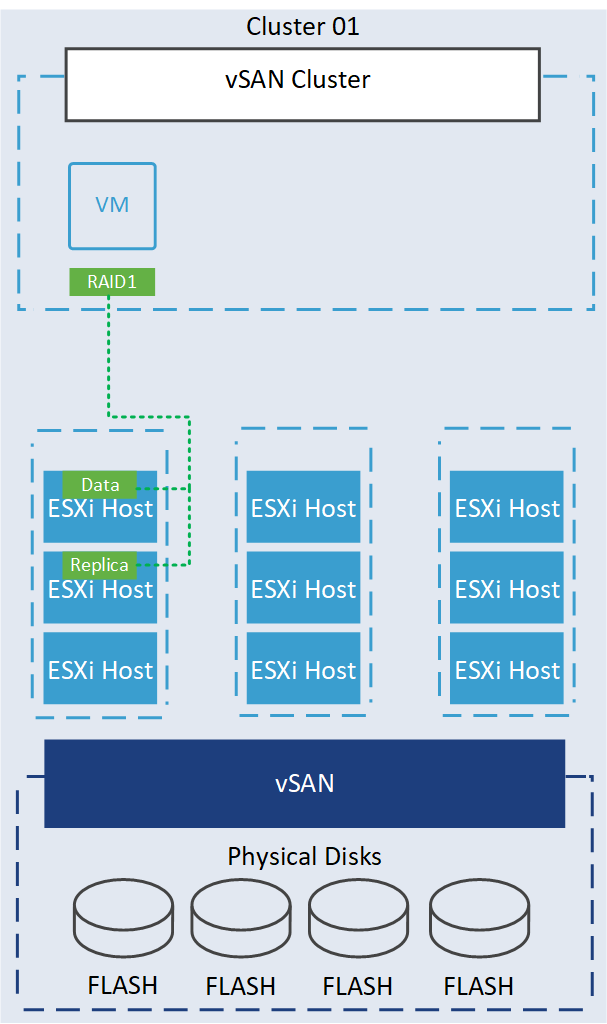
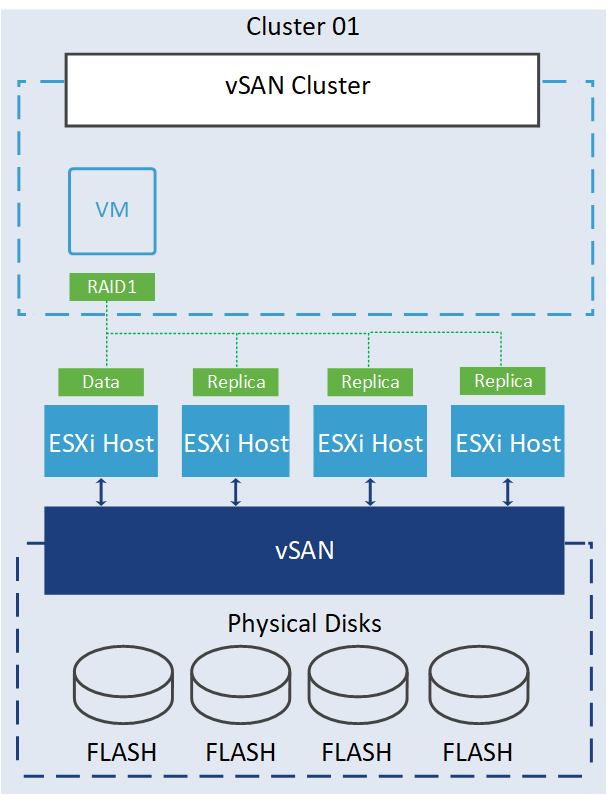
By default, each ESXi host in a vSAN cluster is considered a single Fault Domain. As a result, vSAN cannot guarantee object placement that ensures maximum availability, as it lacks awareness of the underlying rack or blade chassis infrastructure. For example, when data is written to the vSAN cluster using these configurations:
- Site Disaster Tolerance: None (standard cluster)
- Failures to tolerate: 1 failure – RAID-1 (Mirroring).
vSAN will place two copies of the data in different fault domains to ensure data availability and protection against failures, but, since I didn’t configure any fault domains and by default, each ESXi host in vSAN considers one fault domain, it may place the data copies in the same rack (picture above). Therefore, if a hardware failure occurs in the first rack, affecting all three hosts in that rack, it could lead to data loss and loss of the replica simultaneously. To prevent such failures, it is crucial to consider configuring fault domains in this situation.
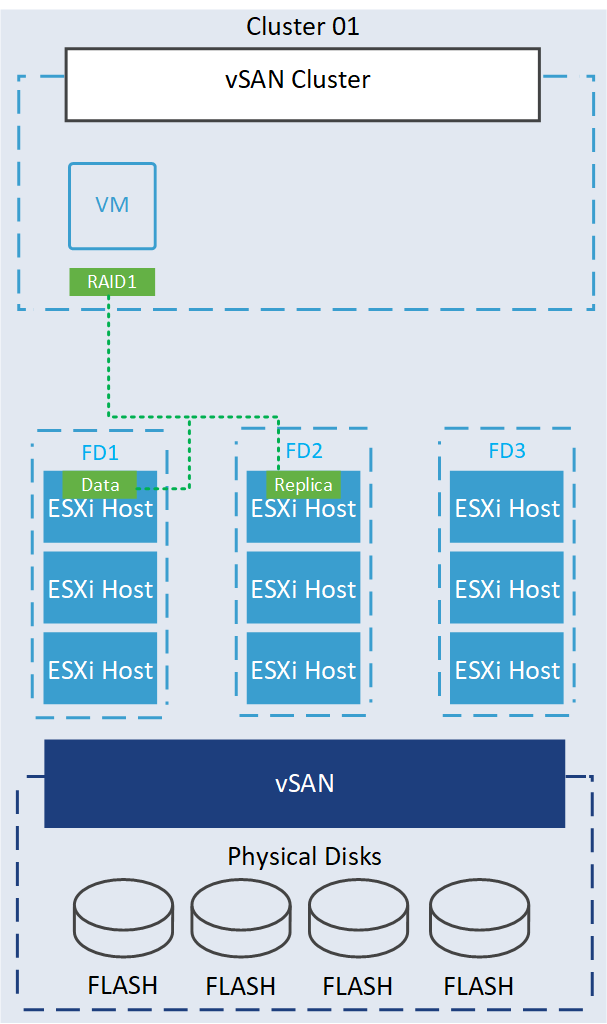
In this situation, vSAN is configured to create a fault domain for each rack, meaning that the hosts and storage devices in each rack are grouped together as a single fault domain. When data is written to the vSAN cluster, vSAN ensures that multiple copies of the data are distributed across the fault domains for redundancy. Here vSAN will place the copy of the data in different fault domains to ensure data availability and protection against failures. Since vSAN has a copy of the data from the first rack spread across the other fault domain (second rack), the data remains accessible and continues to be served even if an entire rack fails, the cluster can still operate without data loss and maintain high availability.
Conclusion
By understanding and effectively utilizing site disaster tolerance, failures to tolerate settings, and fault domains, administrators can design a highly available and flexible vSAN environment that meets their organization’s specific requirements and ensures the seamless operation of virtual machines and data protection within the cluster.
In the next post, I will explore the second tab, stay tuned!
References:
https://core.vmware.com/blog/adaptive-raid-5-erasure-coding-express-storage-architecture-vsan-8
https://core.vmware.com/blog/raid-56-erasure-coding-enhancements-vsan-7-u2
https://core.vmware.com/blog/raid-56-performance-raid-1-using-vsan-express-storage-architecture