This is part of the VMware vSAN guide post series. You can access and explore more objectives from the VMware vSAN study guide using the following link.
In this blog post, I will explore vSAN storage space efficiency techniques to reduce the total storage required capacity and maximize the value of your resources. I have already mentioned some of them in previous posts, but in this post, I will provide a comprehensive overview by consolidating them into one location.
- Deduplication
- Compression
- TRIM/UNMAP
- Thin Provisioning
- RAID Technology
Deduplication
Deduplication is a method that identifies duplicate blocks within data and employs a hash table to point to a single instance of that data block, avoiding the need to store identical blocks multiple times.
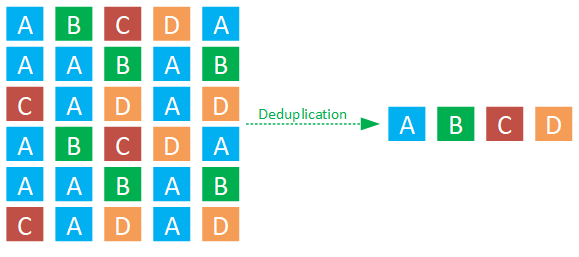
Deduplication is not available in the Express Storage Architecture (ESA) in vSAN 8. Therefore, if you plan to utilize deduplication, you should opt for the Original Storage Architecture (OSA), which is also supported and improved in vSAN 8.
Compression
Compression focuses on optimizing data storage by employing encoding methods to represent the information more efficiently within a given amount of data.

In the ESA, the Compression engine has been moved to the top of the vSAN storage stack. This design helps to compress incoming writes at their point of entry before distributing them between other hosts. This operation is executed only once, and it not only eliminates the necessity to compress data on other hosts holding the object but also reduces the amount of data transmitted across the network. This reduction in CPU and network resource usage is beneficial across the entire cluster.
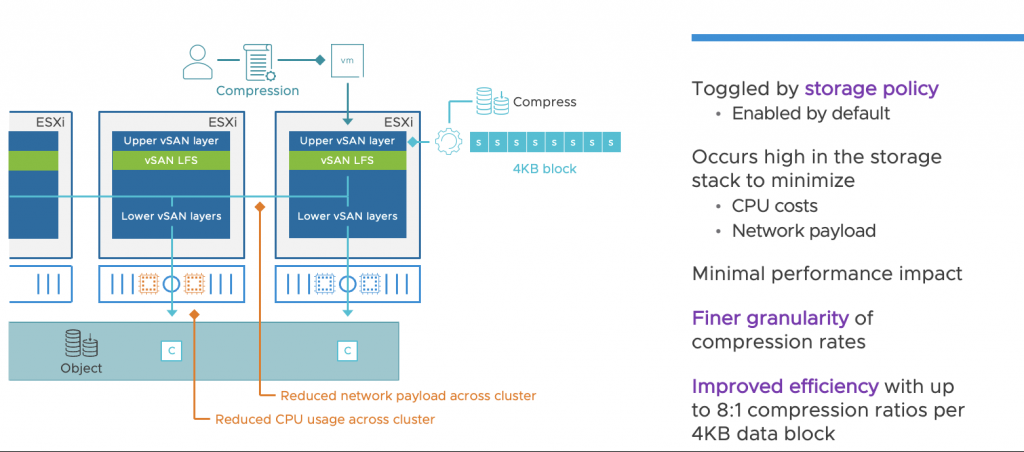
When a guest VM initiates a write operation, it immediately compresses the data as it enters the uppermost layer of the vSAN stack. Each incoming 4KB block is evaluated with a 512 Byte sector size, allowing for data compression at finer granularity levels if the written data is compressible.
Data compression can be managed through storage policies within the vSAN ESA, so it can be enabled or disabled on a per-VM basis. It is enabled by default, and VMware recommends leaving it enabled unless there is a specific application that conducts its own compression.
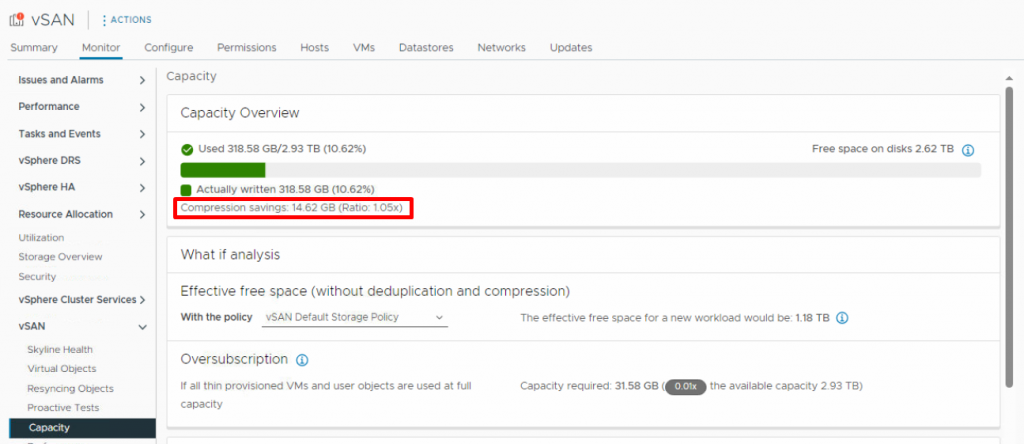
You can check the compression rate and the amount of saved storage space under Capacity in the monitoring tab of the vSAN cluster.
TRIM/UNMAP
TRIM and UNMPA are mechanisms for managing storage space efficiently, Trim is a command in storage systems to mark and free up blocks of data that are no longer needed, improving performance and longevity; Unmap is a command in storage systems to release and reclaim unused storage space, often used in virtualized environments to manage storage efficiently.
vSAN effectively recognizes TRIM and UNMAP commands initiated by the guest OS, enabling it to reclaim previously allocated storage space as free capacity. Imagine you create a virtual machine with a 500GB storage capacity. You proceed to install the operating system, and various applications, and store your data within it. After a year, you decide to remove some data ( for example 200GB) from this virtual machine. However, the VM’s disk size remains at its maximum of 500GB, even after you’ve deleted 200GB of data. Consequently, this leftover unused space cannot be utilized for other purposes or by other virtual machines. This is where TRIM and UNMAP functionality becomes essential and comes into play.
They help ensure that space is reclaimed and made available for new data, which is crucial for maintaining the performance and capacity of vSAN datastores over time.
Thin Provisioning
By default, vSAN provision objects in a thin disk mode, which allocates only the minimum amount of storage needed by objects created on the datastore. It can be defined as the percentage of the size of the object that must be reserved when deploying virtual machines in the vSAN storage policy, as I mentioned in the following post.
If you are planning for thin provisioning and want to check the status of a vSAN datastore, there is an option in vSAN monitoring called ‘Oversubscription.’ This option reports the vSAN capacity required if all the thin-provisioned VMs and user objects are used at full capacity.
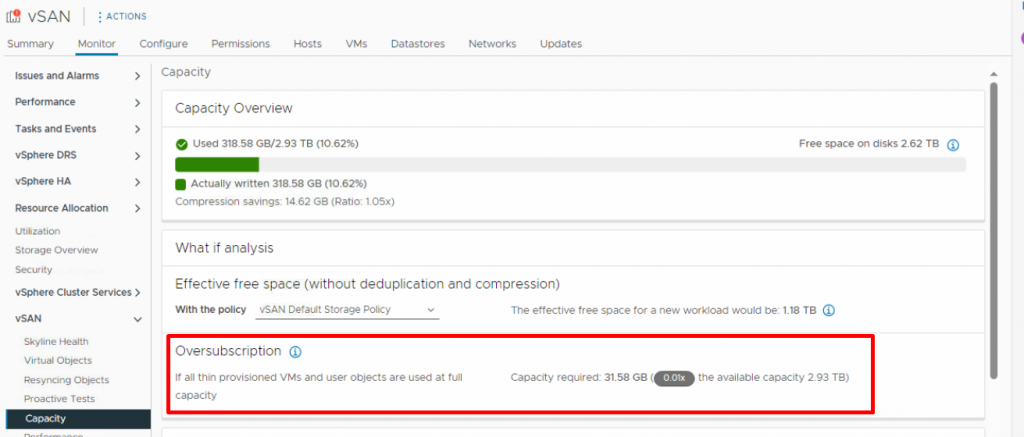
It shows a ratio of the required usage compared with the total vSAN capacity. What if analysis allows you to determine the level of oversubscription and estimate the free space based on the storage policy that you selected.
vSAN includes all the available VMs, user objects, and the storage policy overhead in the calculation of oversubscription and does not consider the vSAN namespace and swap objects.
If you want to pre-allocate the amount of storage capacity on a disk within a vSAN datastore at the time the disk is created, you can configure this using a vSAN storage policy.
RAID Technology
vSAN provides two data protection mechanisms, RAID-1 mirroring duplicate data across multiple hosts, ensuring redundancy and high availability. RAID-5/6 erasure coding distributes data with parity information, allowing for efficient use of storage resources while maintaining resiliency. You can configure these settings and other virtual machine storage requirements, in a vSAN storage policy.
RAID-1 (Mirroring) uses more disk space to store redundant copies of objects, but it provides better performance for accessing these objects. On the other hand, RAID-5/6 (Erasure Coding) uses less disk space, but its performance is relatively reduced. However, in vSAN ESA, you can achieve erasure coding efficiency at RAID-1 performance! This might seem unbelievable, but it’s due to the innovative way the new architecture (Express Storage Architecture) handles I/O.
vSAN ESA also introduced an adaptive RAID-5 Erasure Coding that creates an optimized RAID-5 format based on the cluster size. If the number of hosts in the cluster is less than 6, vSAN creates a RAID-5 (2+1) format. If the number of hosts is greater than 6, vSAN uses a RAID-5 (4+1) format.
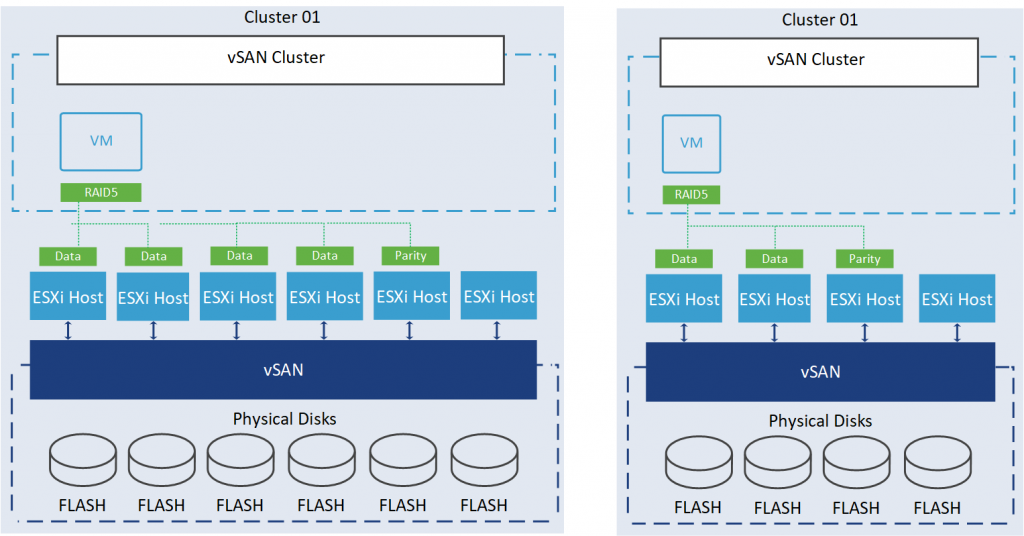
So, we have two schema options: 2+1 and 4+1. You might be wondering why we need at least six hosts in a cluster for the 4+1 schema. This requirement is due to the necessity of having at least one additional host to maintain the recommended level of resilience during subsequent host maintenance modes or in the event of failures.
If you expand or shrink the cluster, the format will be automatically readjusted within 24 hours after the change.
References:
https://core.vmware.com/blog/vsan-8-compression-express-storage-architecture
https://core.vmware.com/blog/adaptive-raid-5-erasure-coding-express-storage-architecture-vsan-8
https://core.vmware.com/resource/vsan-space-efficiency-technologies
https://core.vmware.com/blog/raid-56-performance-raid-1-using-vsan-express-storage-architecture